SEO was for humans. This is for the machines reading on their behalf.
When someone asks ChatGPT, Claude, Grok, or Perplexity about a business, the model isn't pulling from its prettiest landing page. It's pulling from whatever it can cheaply, reliably parse, if it can find anything at all. Most sites were built for human readers and Google's crawler, not for a language model trying to summarise them in one paragraph.
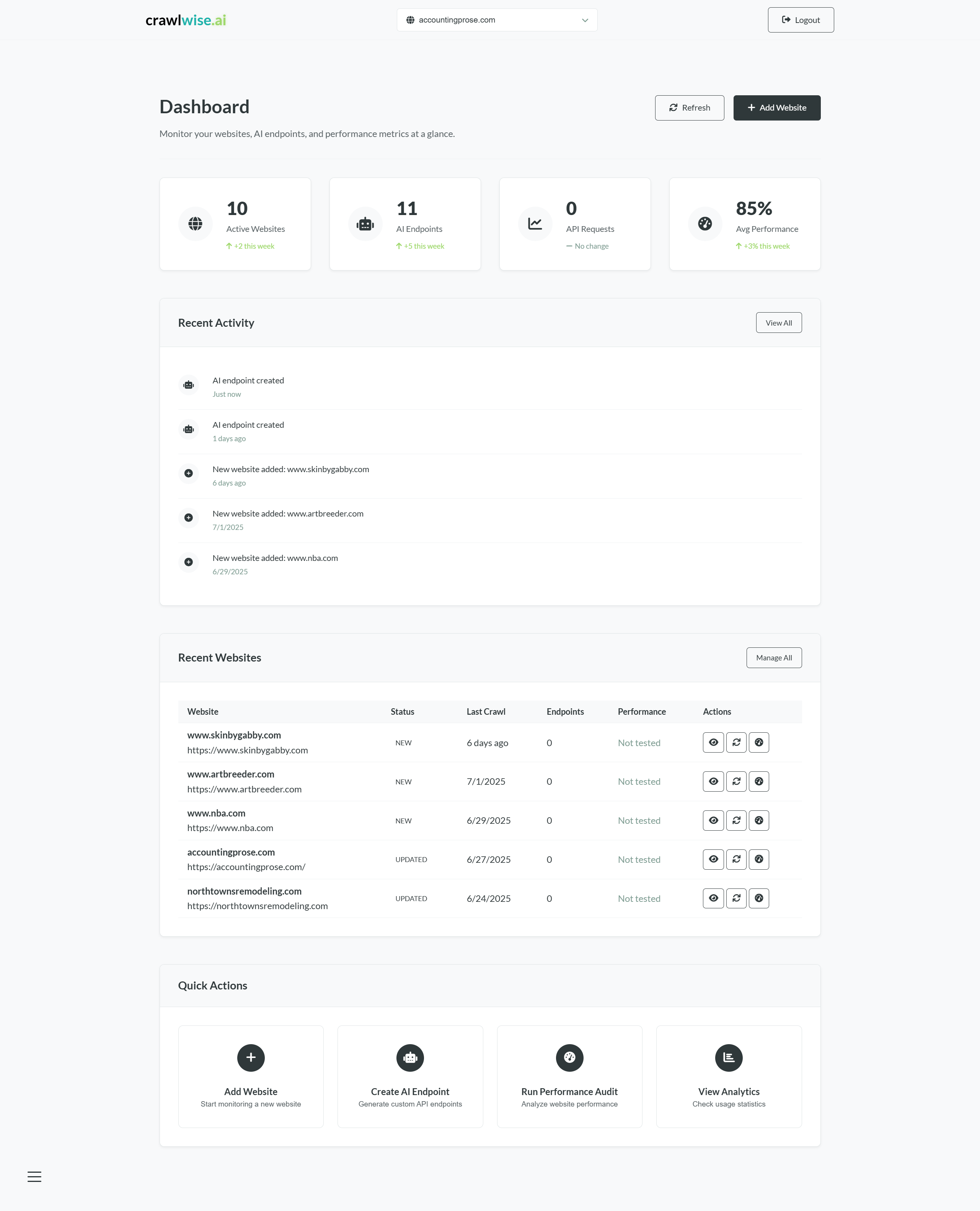
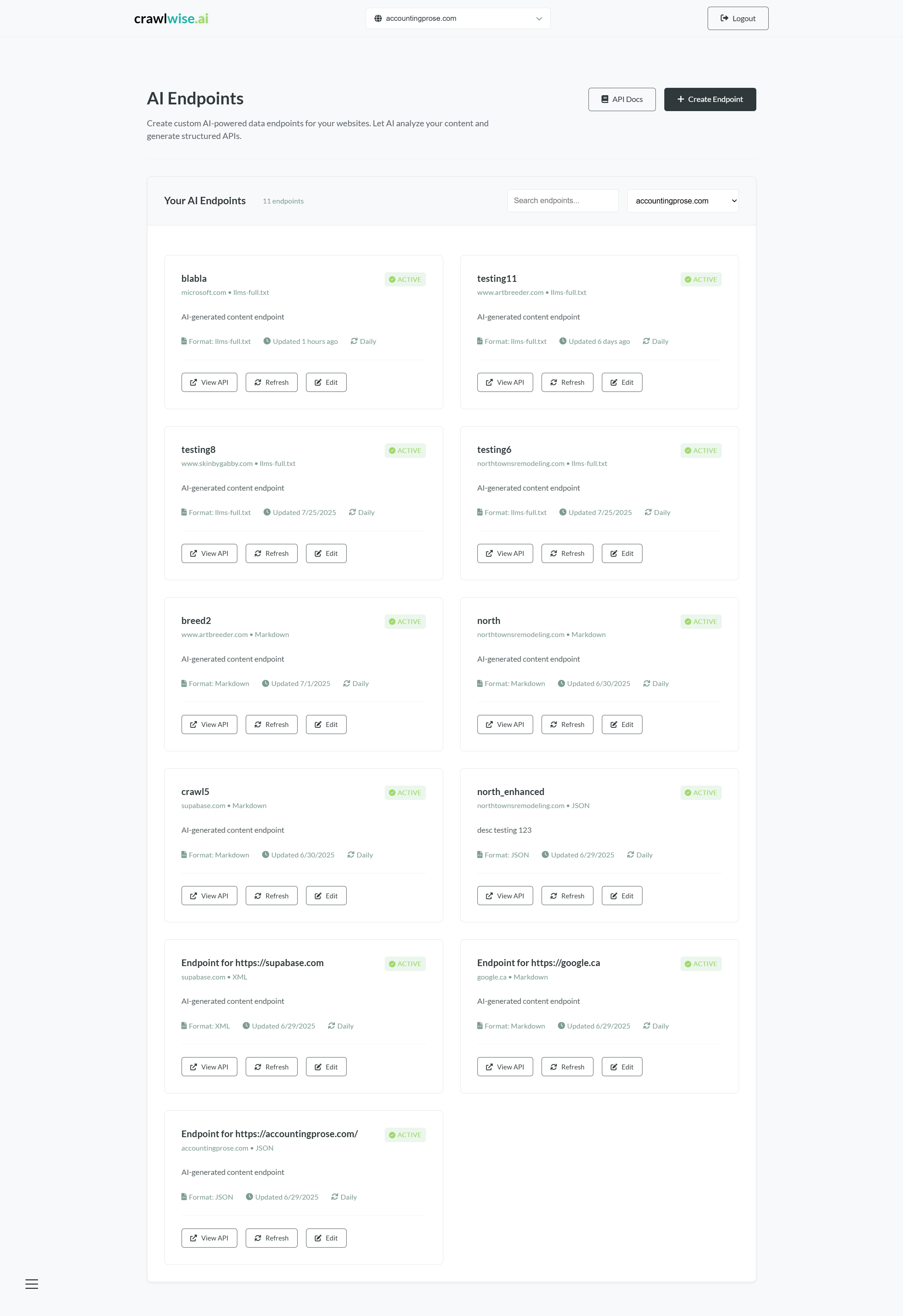
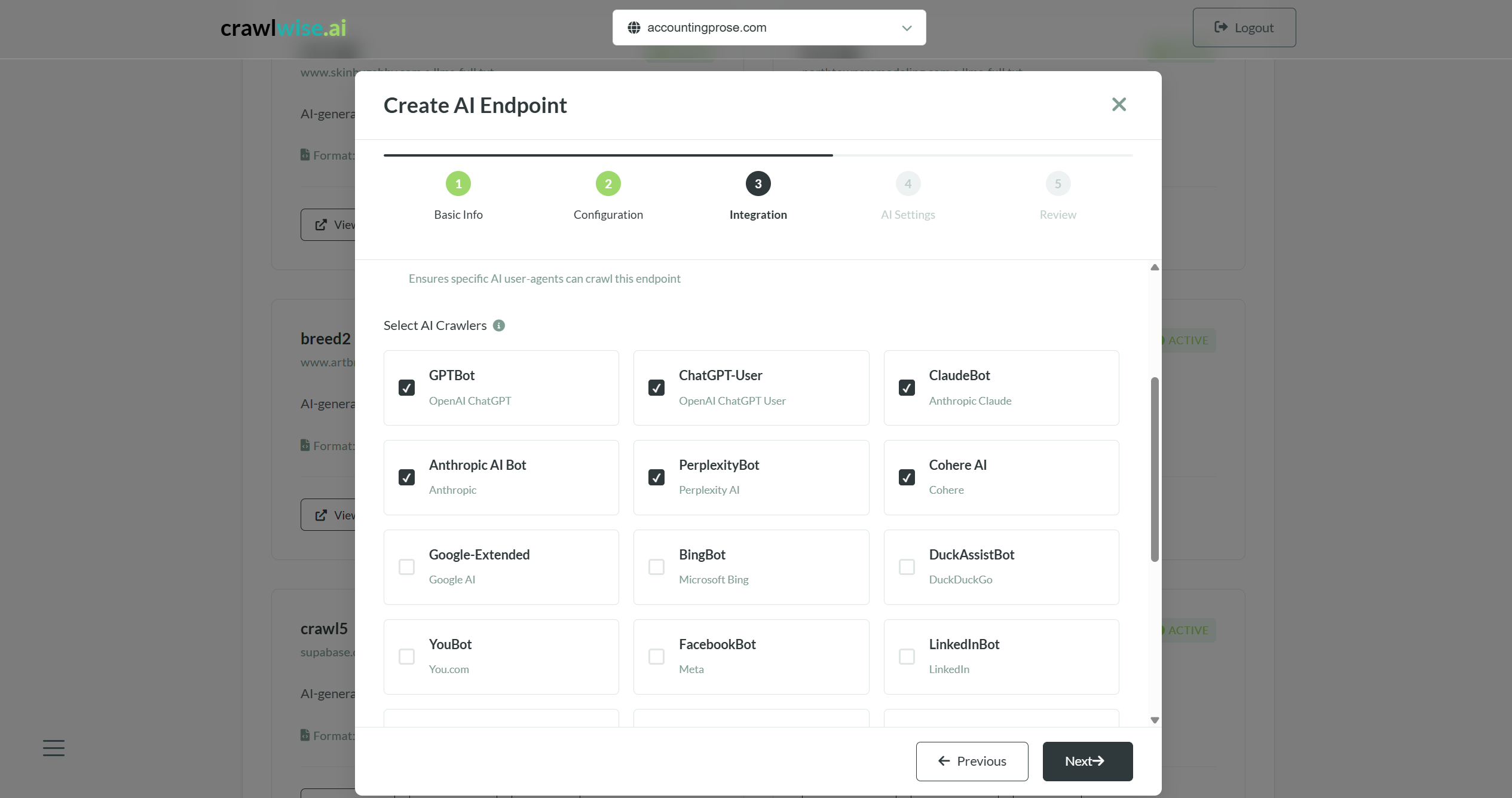
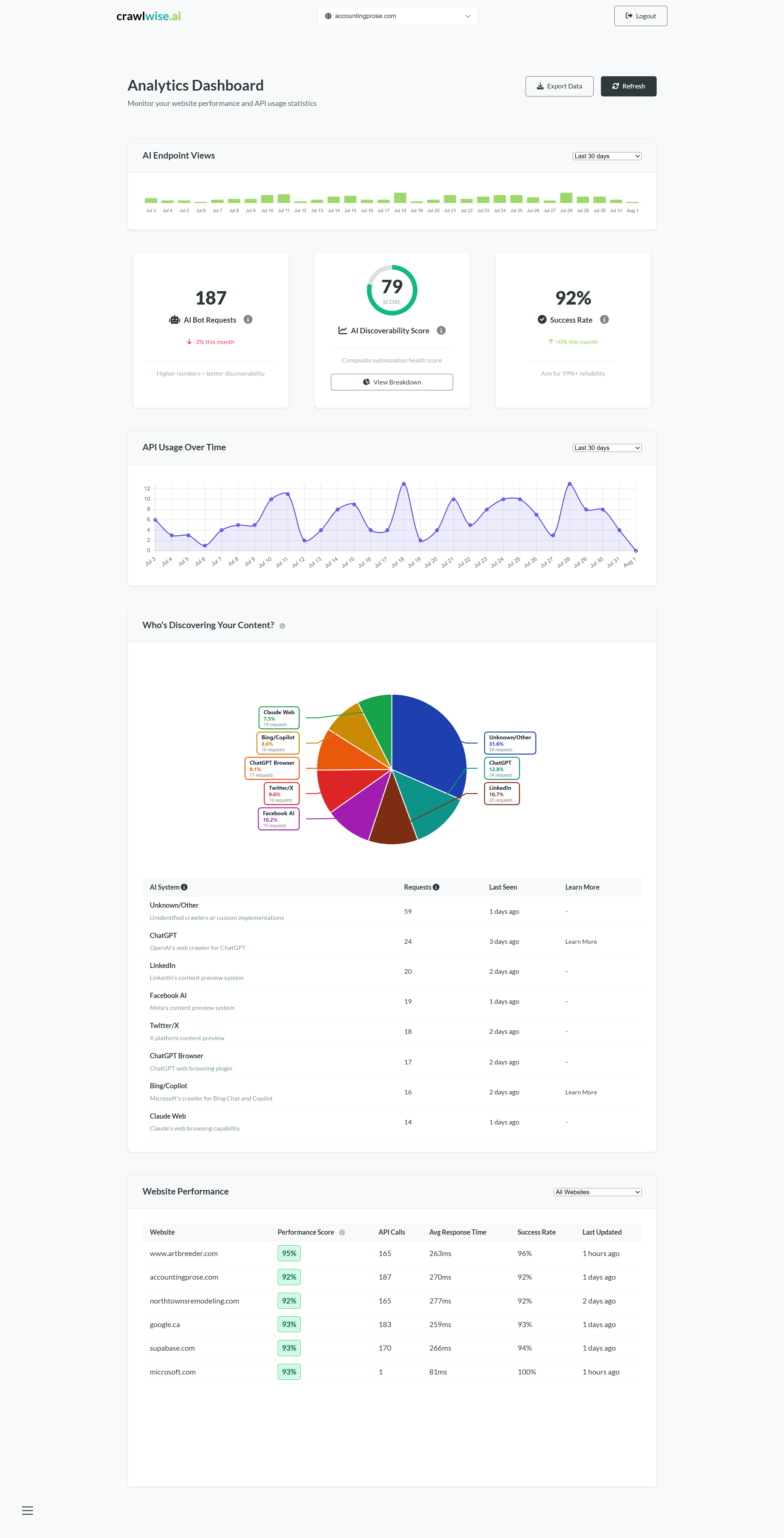
crawlwise.ai closes that gap. Point it at a domain, let Playwright crawl the pages and Cheerio parse them, let a tuned AI pipeline (DeepSeek primary, OpenAI fallback) normalise the content, then publish structured endpoints (llms.txt, llms-full.txt, Markdown, JSON, plain text) that AI crawlers can consume directly. Per-endpoint access rules, a crawler allow-list with 20+ AI user-agents, Lighthouse-backed performance audits, and live analytics on who's asking for what.
The build is a Laitent Space studio project. Free tier covers a structure check, crawlability score, and a starter robots.txt / sitemap; Pro ($19/month) unlocks custom endpoints, schema markup, content-exposure controls, AI interaction analytics, and a simulated-crawl preview of what an AI actually extracts.